
Feature Flags and Why you should use them
You just wrote a great deal of code and are about to deploy it. But you ask yourself, “Will you set the hamsters free to eat all our servers?”
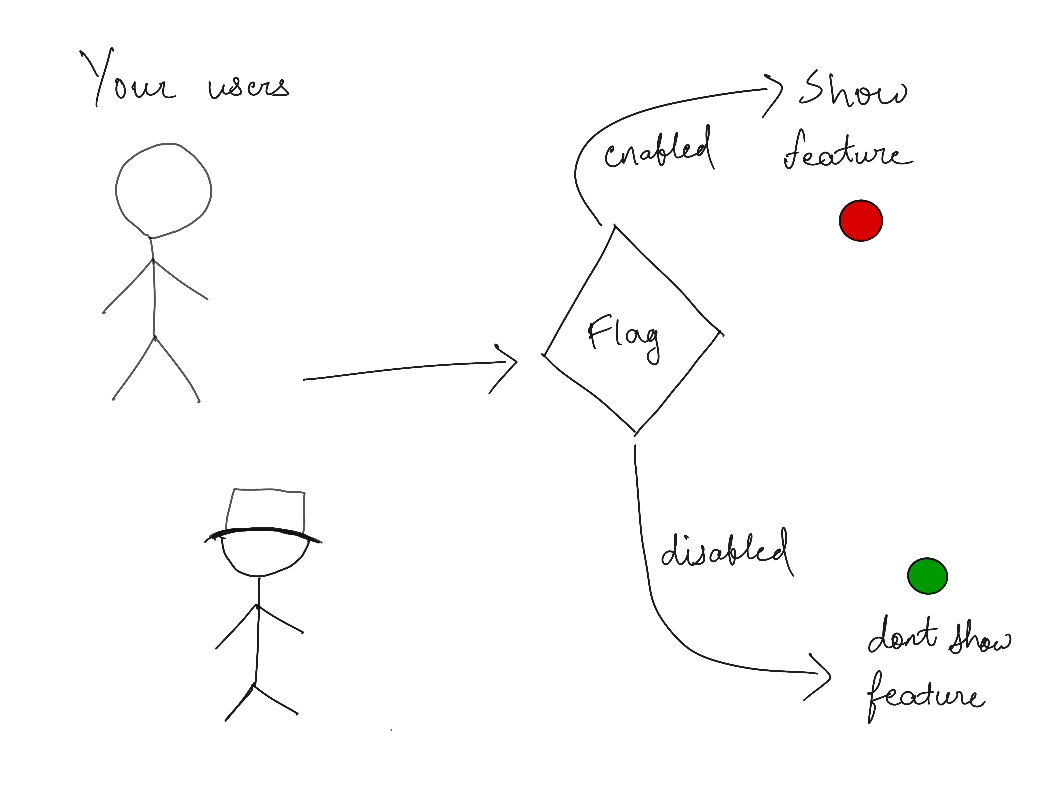
If you find yourself wondering whether your last change will kill your servers or receive extreme bashing from your users, you need feature flags.
Feature flags are a great way to be fast and safe while developing software. They can be used for many things, including A/B testing, canary releases or staged rollouts. You can have your code do one thing for some customers and another for others; you can keep track of how well things are working out; and take appropriate action if something goes wrong.
Feature flagging is an approach to continuous delivery in which we release features by modifying a system configuration rather than changing code. Rather than release all the features simultaneously, you can release specific features to specific users in different environments.
Feature flags are configurable parameters that function as gatekeepers for enabling or disabling one or more features based on some condition that can be static or dynamic. They’re ideal for managing user experience or feature rollouts since they allow you to control when new features are activated or deactivated. Combining them with product analytics and error monitoring, you can also monitor how users interact with them before starting them for everyone.
def get_homepage_content(request):
if feature_flags.enabled('new_homepage', request):
return new_homepage(request.user)
else:
return homepage_content(request.user)How are Feature Flags helpful to you?
Feature flags are a tool that can help you deliver complex products faster. They provide safety, agility, release control, and experimentation support.
Safety: Being able to turn off things that aren’t working immediately. The ability to scale up safely.
Turning off things that aren’t working immediately is an obvious benefit, but it’s not the only one. You can also increase your team’s velocity by enabling them to implement changes faster without worrying whether those changes will ruin everything else. When you’re using feature flags and can scale down quickly, you don’t have to worry about removing unpopular features from your codebase if they don’t work out. And if there are any bugs or issues with a new piece of code or feature, it’s easy to disable it while you resolve them instead of having your whole system go down when something breaks unexpectedly at runtime!
Agility and Release Control - release your new features faster while not affecting the functionality of your current features.
You can now safely test new features without affecting the functionality of existing features. You can release features to a small subset of users and see how they work. If you find something that does not work as expected, you can quickly shut it off for all users or just for that subset.
You don’t need to code features that you want to experiment with in advance or choose between deploying sooner but potentially risking downtime or delaying your deployment and allowing other teams’ work to back up behind you. You can test new features in an isolated environment and then release them as soon as they’re ready—without having to plan for it months in advance.
Feature flags work exceedingly well with the CI/CD philosophy, which empowers users to deploy code once it’s merged with the mainline and passes all acceptance tests by toggling off all the new changes. Once all the features pass QA, you can turn them on.
Experimentation: determine whether a new or changed feature works as intended and whether it should be a part of the general release.
Another benefit of feature flags is experimenting with a new or revised feature and determining whether it works as intended. If you don’t need the new or revised feature for the general release, you can turn it off entirely and avoid any negative impact on the user experience.
In addition, if there are features that work well but aren’t making their way into your general releases, this allows you to test out new ideas and see if they are helpful before deploying them widely. And finally, by getting feedback from users who opt into these experiments, you can get a sense of what they want to help shape future updates.
A/B Testing: You might think you don’t need feature flags for this—you’re just going to run a couple of experiments simultaneously. But what if you wanted to run a test where not all customers see the same variation? Or what if you wanted to measure the impact of each variation independently? Feature flags let you do both of these things quickly!
Canary Releases: Canary releases are a great way to get early feedback on new software. You can use feature flags to enable the new code for only part of your customer base and then gradually roll it out further as you collect data and ensure everything works as expected.
Staged Rollouts: This is similar to A/B testing, except that instead of measuring how different groups respond differently to the same thing, you measure how the same group reacts differently over time.
Implementing feature flags
Classifying feature flags
We can classify feature toggles into multiple classes based on their longevity and dynamism. Based on this, we can bin them into
Release flags - set during build time to enable/disable code sections.
Experiment flags - enable A/B testing.
Ops flags - the ability to turn features off if something goes wrong.
Permission toggles - allow certain features for a subset of users.
Release flags
They are the least dynamic of the bunch, and you set them during build time. You can use it to disable features that need to be conditioned or fail a late-stage QA review—often used by teams following trunk-based development to exclude changes that are not yet ready.
You can implement release flags by language/build tool features such as #IFDEF macros in C++ to include and exclude code.
A famous use of release flags is noticeable in APK teardowns, where insights into strings disabled in application code give a sneak peek of what’s coming in future versions but is not currently ready for prime-time.
Experiment flags
Used for A/B testing, enable a feature based on which cohort a user belongs to. You can serve two versions of your code to different cohorts of users and observe the performance of the versions. Since the flags depend on some properties of the current user, you decide the feature flag value on runtime. Typically, you call an API with user details, which gives the flag’s value. There are several libraries and third-party services that help implement feature flags.
Ops Flags
These flags control operational aspects of our code. You may consider an ops flag when rolling out a new feature that risks breaking a critical flow or has unclear performance implications. If the feature misbehaves, developers can quickly disable the recent changes using these flags.
Such flags are designed to be relatively short-lived - once we achieve confidence in the new change, we remove the flag. However, systems also have a few “Kill Switches” that allow disabling non-critical system functionality when the system is under unusually high load or dealing with a failing third party such as a payment gateway.
Since ops flags don’t depend on user context, You can implement ops flags by reading them from environment variables or configuration stores such as Consul or Etcd.
Permission toggles
You may want to expose newly introduced features to a small group of users - such as internal users or alpha/beta users for early feedback based on which you may further evolve the product. Such flags are the most dynamic of the bunch are depend on the user’s configuration.
A typical way of implementing this would be to tag features based on their availability and decide to expose them based on whether the user belongs to the group for which we expose this functionality.
Considerations while implementing feature toggles
Separating decision points from decision logic
While developing feature flags, it is increasingly tempting to splatter a bunch of if-else all over your code and control features based on this. It may seem reasonable, but it tightly couples feature flags with features. For example, consider yourself developing many changes for a v2 iteration of a workflow.
def generate_report(query):
if feature_flags.enabled("v2_release"):
add_performance_data()
# ...
if not feature_flags.enabled("v2_release"):
# do some deprecated work.
Such code forces you to release everything together or nothing at all. However, if you want to release a subset of features, you can only do so with extensive refactoring. Also, breaking into many small feature flags would be too much to handle.
Instead, a more innovative way would be to introduce another abstraction that does context-specific decisions using feature flags.
Let’s refactor the above code.
# report_features.py
def performance_data_enabled():
return feature_flags.enabled("v2_release")
def query_source_table():
return not feature_flags.enabled("v2_release")
# generate_report.py
def generate_report(query):
if report_features.performance_data_enabled():
add_performance_data()
# ...
If report_features.query_source_table():
# do some deprecated work
Embracing Inversion of Control
Decision-based strategies like the above work well for simple changes, but adding so many branching points would be a maintenance headache when changes become non-trivial.
Feature flags go well with the Open-Close principle of SOLID practices. Instead of changing existing code, you can develop and switch a new implementation based on feature flags.
class V1ReportGenerator:
def generate_report():
# do work
class V2ReportGenerator:
def generate_report():
# do more work
def create_report_generator():
if feature_flags.enabled("v2_release"):
return V2ReportGenerator()
else
return V1ReportGenerator()
Storing feature flag data
If possible, prefer storing them alongside your code in your SCM and re-deploy whenever you enable or disable a feature. Managing flags in code gives the same benefit as infrastructure as code and contains a log of what changes you deployed at any time.
You can store flags in the app database for more dynamic features. The schema for storing flags can be straightforward – a feature name, value, and additional columns for conditions and audit metadata. You can also use other data stores such as Consul or Etcd.
Managing overrides
There will be cases where you must toggle a flag for a minimal subset of users. Having a proper overriding mechanism can help here.
If you are using a database, you can maintain an override table with additional constraints on which you perform a left join to get the value of a feature flag.
You can also opt for additional information from the request context - such as an API version or a special HTTP header to control feature flags. Doing this moves the control of flags to the consumer of your service.
There are many different ways to use feature flags, but the main idea is simple: you can use them to roll out new features without breaking your site, which means no more worrying about code deployment and issues with testing. If a component isn’t ready for prime time, flip the switch off until it’s ready.
The concept of feature flags is pretty simple: they allow you to control which users see each feature on any given day or week as it rolls out slowly over time rather than all at once when deployed and live. This means fewer bugs in production because tests are more accessible and faster than ever!